





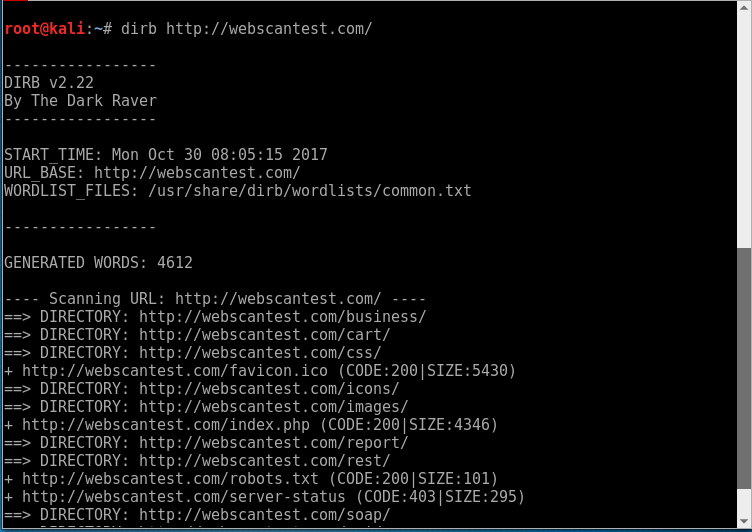
Certains contenus sur les sites Web sont apparemment cachés – c’est-à-dire que sans avoir leur adresse, nous ne sommes pas en mesure de les atteindre. Souvent, ce sont quelques restes encore de l’étape de la création de l’application – le développeur a été plus tard les supprimer, mais a oublié ̄_(ツ)_/ ̄ .
Avec l’aide de trouver de tels contenus, nous sommes aidés par l’outil DIRB. Il s’est fait en se référant à l’adresse indiquée et en analysant la réponse du serveur. L’outil de son package contient des dictionnaires préconfigurés avec les emplacements les plus courants sur les sites Web. Bien entendu, nous pouvons également utiliser notre liste de mots.
Outil à télécharger à partir de: DIRB
